Certaines considérations sont à prendre en compte lors de la mise en place du pool de stockage container ou lors de la migration des pools de stockage classiques vers du container.
Concept des données dédupliquées
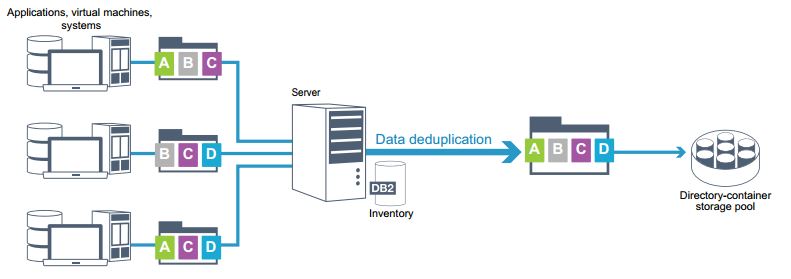
Lorsque le serveur Spectrum Protect reçoit les données d’un client, il identifie les extensions de données identiques et stocke uniquement les nouvelles dans le pool de stockage container.
A savoir
Si les mêmes blocs sont envoyés plusieurs fois, le pool de stockage container réduit considération la quantité de données stocker sur ce pool. De même, Spectrum Protect déduplique aussi une partie de fichier commun reçue avec d’autres parties de fichier commun.
Déduplication côté serveur
Le serveur identifie les extensions de données en double et déplace les données dans le pool de stockage contenair.
Le processus côté serveur utilise la déduplication de données en ligne, où elles sont dédupliquées en même temps qu’elles sont écrites dans le pool de stockage contenair. La déduplication de données en ligne sur le serveur offre les avantages suivants:
- Élimine le besoin de récupération (Reclaim)
- Réduit l’espace occupé par les données stockées
Déduplication côté client
Avec cette méthode, le traitement est distribué entre le serveur et le client lors d’une opération de sauvegarde.
Le client et le serveur identifient et suppriment les données en double pour sauvegarder l’espace de stockage sur le serveur.
Dans la déduplication de données côté client, seules les données compressées et dédupliquées sont envoyées au serveur.
Le serveur stocke les données dans le format compressé fourni par le client. La déduplication de données côté client offre les avantages suivants:
- Réduit la quantité de données envoyée sur le réseau local (LAN)
- Élimine la puissance et le temps de traitement supplémentaires requis pour supprimer les données en double sur le serveur
- Améliore les performances de la base de données car la déduplication de données côté client est également en ligne
Vous pouvez combiner la déduplication de données côté client et côté serveur dans le même environnement de production.
La possibilité de déduplication des données sur le client ou sur le serveur offre une flexibilité en matière d’utilisation des ressources,
de gestion des politiques et de protection des données.
Compression
Utilisez la compression en ligne permet de réduire la quantité d’espace stockée dans les pools de stockage de container.
Restriction:
Le serveur IBM Spectrum Protect ne peut pas compresser les données cryptées.
Quelques recommandations à prendre en compte lors du passage au pool de stockage container
Lors du passage au pool de stockage container, la base de données DB2 s’agrandit. Il faut compter en général 100Go de données supplémentaires dans la base de données pour 10To de données sauvegarder. Il faut prendre ces 10To en mode dédupliqué.
Lors d’une migration d’un pool de stockage File vers Container, la Log et Archivelog se remplissent fortement, il faut :
- Agrandir la Log de Spectrum Protect à au moins 128Go
- Effectuer des sauvegardes de la DB plus souvent, afin de vider les archivelogs
Avant de lancer la migration d’un pool de stockage file vers container, il faut absolument:
- Rediriger toutes les sauvegardes sur le pool de stockage container. Le pool de stockage file ne doit plus être alimenté en données
- Exécuter le processus de »Backup STG file vers STG Copy » (permettant d’avoir une sécurité en cas d’erreur de conversion, retour arrière possible)
A savoir
Si le processus de »Backup STG vers STG Copy » n’a pas eu lieu, lors de la conversion des données, le pool de stockage initial ne supprimera pas les données au fil de l’eau mais seulement à la fin du processus de migration.
Restriction
Vous ne pouvez utiliser aucune des fonctions suivantes avec les pools de stockage container:
- Migration
- Reclamation
- Aggregation
- Collocation
- Export/Import
- Simultaneous-write
- Storage pool backup
- Virtual volumes
Vous ne pouvez pas convertir les pools de stockage suivants vers du container:
- Pool de stockage primaire (DISK)
- Pool de stockage de copie
- Pool de stockage active
Les avantages du pool de stockage container
- Pas de Reclamation des données
- Le processus de copie sur bande ne réhydrate pas la donnée. Le processus de copie est beaucoup plus rapide qu’avec la déduplication de type File
- Le ratio de déduplication est beaucoup plus élevé (retour terrain : une infrastructure VMware sauvegardée en déduplication de type file permet d’avoir un taux de réduction de 40-45%, avec la déduplication de type container, on arrive à un taux de réduction de 65-70%)
Prérequis au pool de stockage container
- Utilisez des disques SSD pour la base de données DB2
- S’assurer que la base de données DB2 a une disponibilité d’au moins 3000 IOPS et pour chaque TB sauvegarder quotidiennement ajouter 1000 IOPS au minimum. Donc pour 3TB journaliers, il faut compter au moins 6000 IOPS.
- Compter au minimum 40GB de mémoire sur le serveur pour une base de données de 100GB. Ajouter de la mémoire afin d’améliorer le cache page de la base de données.
- Il faut compter 128GB de mémoire sur le serveur, pour une base de données entre 1 – 2TB
- Il faut compter 192GB de mémoire sur le serveur, pour une base de données entre 2 – 4 TB
- L’activelog doit être positionné à 128GB (ACTIVELOGSIZE 131072)
- Il est recommandé d’avoir une archivelog de 1TB (s’assurer qu’il reste toujours, au moins 10% de disponible)
- Ajouter l’option ARCHLOGCOMPRESS sur l’instance Spectrum Protect (attention, à ne pas activer pour une sauvegarde quotidienne dépassant les 6TB)
Lien reprenant toutes ces recommandations:
PRA
Il existe plusieurs solutions de PRA en pool de stockage container, je vais en citer deux.
Le PRA avec la fonction « Replicate Node »
Solution de protection des données avec IBM Spectrum Protect sur disque.
Spectrum Protect utilise la déduplication (pool de stockage container) et la réplication de données en ligne dans deux sites.
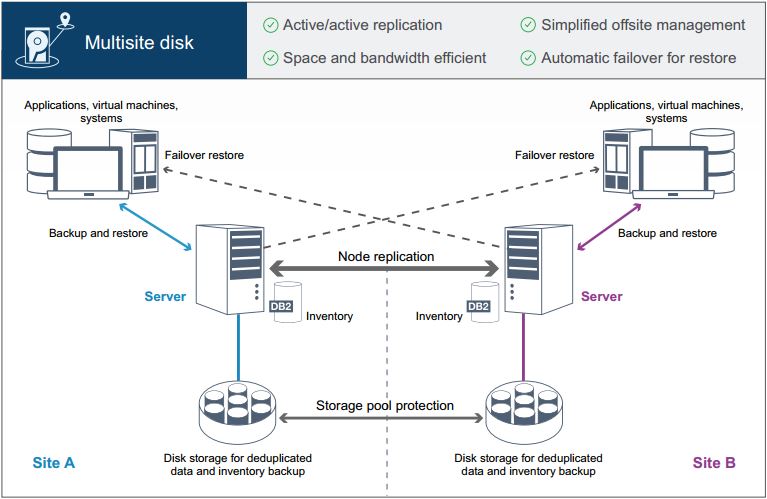
Cette solution de protection de la donnée offre les avantages suivants:
- La réplication peut être configurée sur les deux sites afin que chaque serveur protège les données de l’autre
- Le stockage de données hors site pour chaque emplacement est simplifié
- La bande passante est utilisée efficacement car seules les données dédupliquées sont reproduites entre les sites
- Les clients peuvent basculer automatiquement sur le serveur de réplication cible si la source n’est pas disponible
Dans cette solution, les clients envoient des données au serveur source, où les données sont dédupliquées et stockées dans un pool de stockage de
répertoires-conteneurs.
Les données sont répliquées dans le pool de stockage sur le serveur cible sur chaque site distinct. Cette solution convient aux environnements nécessitant une protection contre les sinistres. En cas de catastrophe, les clients d’un des deux sites peuvent utiliser les données par basculement de site, pour les sauvegardes et la récupération de données à partir du serveur disponible sur l’autre site.
Le PRA à froid
Solution de protection des données avec IBM Spectrum Protect sur bandes. Plusieurs lecteurs de bandes pour copier les données. La bande apporte des coûts peu coûteux. Évolutivité optimisée pour la rétention à long terme.
Lors d’un sinistre, il faudra :
- Restaurer la base de données Spectrum Protect
- Auditer toutes les bandes des STG de copie
- Lancer le processus de restauration du ou des pool(s) de stockage container (impossibilité de restaurer des données directement de la bande de copie, où réside des données Container)
- A la fin de la tâche 4, lancer la restauration des clients